Genealogy
This document provides a high-level overview of how to use Rhize for material genealogy.
In manufacturing, a genealogy is the record of what a material contains or what it is now a part of. As its name implies, genealogy represents the family tree of material. A material genealogy helps manufacturers in multiple ways:
- Prevent product recalls by isolating deviations early in material flow
- Decrease recall time by maintaining a complete record of where material starts and ends
- Build reports and analysis of material deviations
- Create documentation and compliance records for material tracking
Rhize provides a standards-based schema to represent material at all levels of granularity. The graph structure of its DB has built-in properties to associate material lots with other information about planned and performed work. This database has a GraphQL API that can pull full genealogies from terse queries. Rhize makes an ideal backend for genealogical use cases.
Data from a Rhize query in an Apache Echart. Read the Build frontend section for details.
Quick query
To get started with genealogy quickly, use these query templates. One template is for the reverse genealogy, and the other is for the forward genealogy. For each, you need to input the Lot ID.
query reverseGenealogy{
getMaterialLot(id: "<LOT_ID>") {
parent_lots: isAssembledFromMaterialLot {
id
grandparent_lots: isAssembledFromMaterialLot {
id
great_grandparent_lots: isAssembledFromMaterialLot {
id
}
}
}
}
}query forwardGenealogy{
getMaterialLot(id: "<LOT_ID>") {
child_lots: isAssembledFromMaterialLot {
id
grandchildren_lots: isAssembledFromMaterialLot {
id
great_grandgrandchildren_lots: isAssembledFromMaterialLot {
id
}
}
}
}
}You can modify the query to include more fields, levels, or get the forward and backward genealogy. For an idea of how a more complete query would look, refer to the Examples section.
Background: material entities in Rhize
In ISA-95 terminology, the lineage of each material is expressed through the following entities:
- Material lots. Unique amounts of identifiable material. For example, a material lot might be a camshaft in an engine or a package of sugar from a supplier.
- Material Sublots. Uniquely identifiable parts of a material lot. For example, if a box of consumer-packaged goods represents a material lot, the individual serial numbers of the packages within might be the material sublots. Each sublot is unique, but multiple sublots may share properties from their parent material lot (for example, the expiry date).
The relationship between lots is expressed through the following properties:
isAssembledFromMaterial[Sub]lotandisComponentOf[Sub]lot. The material lots or sublots that went into another material.parentMaterialLotandchildSubLot. The relationships between a material lot and its sublots.
Note that these properties are symmetrical. If lot final-1 has the property {isAssembledFromMaterialLot: "intermediate-1"},
then lot intermediate-1 has the property {isComponentOfMaterialLot: "final-1" }.
The graph structure of the RhizeDB creates these links automatically.
Steps to use Rhize for genealogy
The following sections describe how to use Rhize to build a genealogy use case. In short:
- Identify the unique lots in your material flows.
- Add these lots to your model.
- Implement how to collect these lots.
- Query the database.
The example uses a simple baking process to demonstrate the material flow.
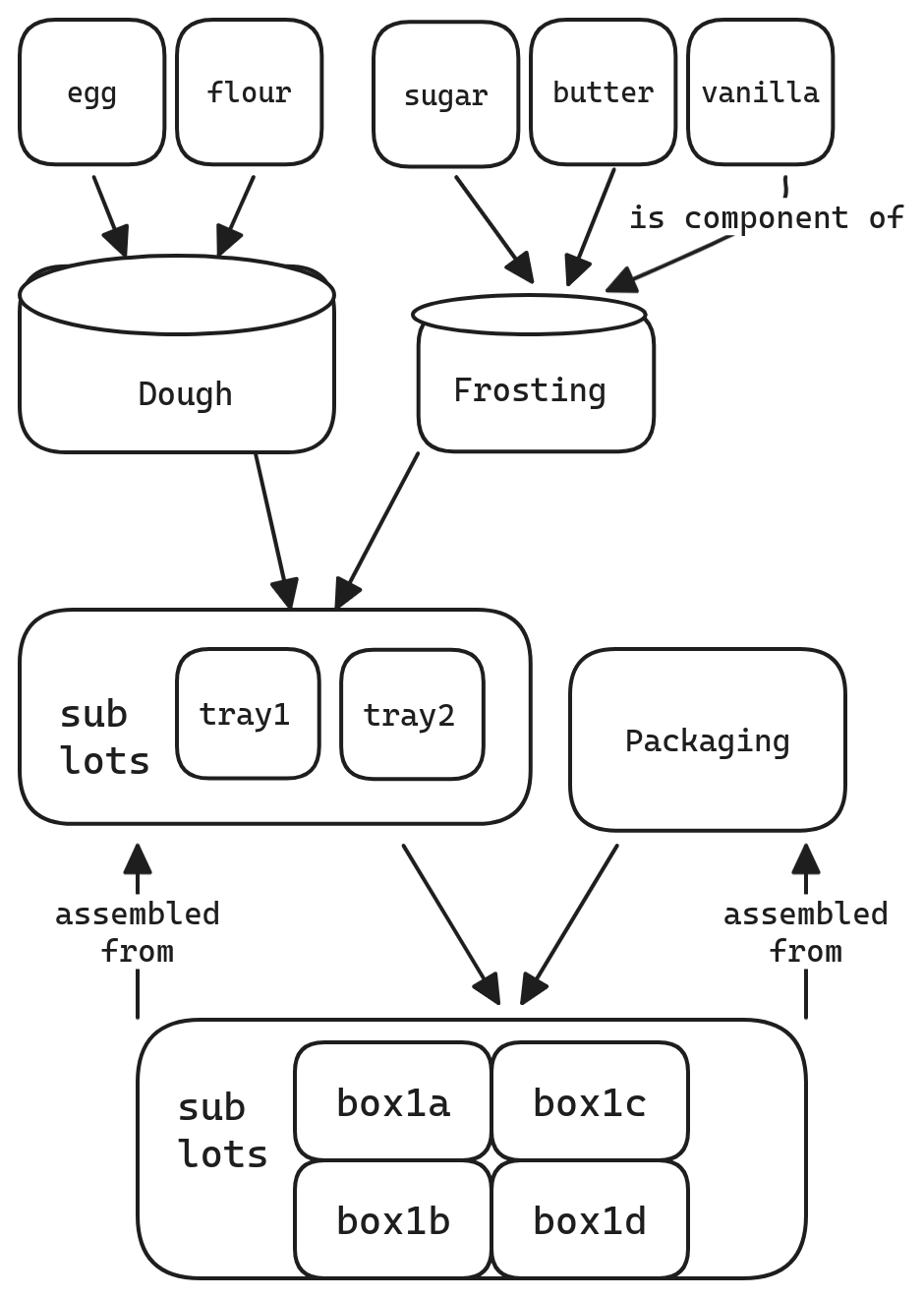
Identify lots to collect
To use Rhize for genealogy, first identify the material lots that you want to identify. How you identify these depends on your processes and material flows. The following guidelines generally are true:
- The lot must be uniquely identifiable.
- The level of granularity of the lots is realistic for your current processes.
For example, in a small baking operation, lots might come from the following areas:
- The serial numbers of ingredients from suppliers
- The batches of baked pastries
- The wrappers consumed by the packing process
- The pallets of packed goods (with individual packages being material sublots).
Model these lots into your knowledge graph
After you have identified the material lots, model how the data fits with the other components of your manufacturing knowledge graph. At minimum, your material lots must have a material definition with an active version.
Beyond these requirements, the graph structure of the ISA-95 database provides many ways to create links between lots and other manufacturing entities, including:
- A work request or job response
- The associated resource actual
- In aggregations such as part of a material class, or part of the material specifications in a work master.
In the aforementioned baking process, the lots may have:
- Material classes (raw, intermediate, and final)
- Associated equipment (such as
mixers,ovens, andtrays) - Associated segments (such as
mixingorcooling) - Associated measurements and properties
Implement how to store your lots in the RhizeDB
After you have planned the process and defined your models, next implement how to add material lot IDs to Rhize in the course of your real manufacturing operation.
Your manufacturing process determines where lot IDs are created. The broad patterns are as follows:
- Scheduled. Assign lots at the time of creating the work request or schedule (while the job response might create a material actual that maps to the requested lot ID).
- Scheduled and event-driven. Generate lot IDs beforehand, and then use a GraphQL call to create records in the Rhize DB after some event. Example events might be a button press or an automated signal that indicates the lot has been physically created.
- Event-driven. Assign lot IDs at the exact time of work performance. For example, you can write a BPMN workflow to subscribe to a topic that receives information about lots and automatically forwards the IDs to your knowledge graph.
In the example baking process, lots may be collected in the following ways:
- Scanned from supplier bar code
- Generated after the quality inspector indicates that a tray is finished
- Planned in terms of final package number and expiration date
Query the data
After you start collecting data, you can also start querying it through the materialLot query operations.
The following section provides example genealogy queries.
Examples
The following examples show how to query for forward and backward genealogies using the get operation to query material lots.
Backward genealogy
A backward genealogy examines all material lots that make the assembly of some later material lot.
In Rhize, you can query this relationship through the isAssembledFromMaterialLot property,
using nesting to indicate the level of material ancestry to return.
For example, this returns four levels of backward genealogy for the material lot
cookie-box-2f (using a fragment to standardize the properties returned for each lot).
query{
getMaterialLot (id:"cookie-box-2f") {
...lotFields
isAssembledFromMaterialLot {
...lotFields
isAssembledFromMaterialLot {
...lotFields
isAssembledFromMaterialLot {
...lotFields
}
}
}
}
}
}
## Common fields for all nested material
fragment lotFields on MaterialLot{
id
quantity
quantityUnitOfMeasure{id}
materialDefinition{id}
}The returned genealogy looks something like the following:
example-backward-genealogy.json
{
"data": {
"getMaterialLot": {
"id": "cookie-box-2f",
"quantity": 1,
"quantityUnitOfMeasure": {
"id": "cookie box"
},
"materialDefinition": {
"id": "cookie-box"
},
"isAssembledFromMaterialLot": [
{
"id": "cookie-unit-dh",
"quantity": 1000,
"quantityUnitOfMeasure": {
"id": "cookie unit"
},
"materialDefinition": {
"id": "cookie-unit"
},
"isAssembledFromMaterialLot": [
{
"id": "cookie-frosting-9Q",
"quantity": 3500,
"quantityUnitOfMeasure": {
"id": "g"
},
"materialDefinition": {
"id": "cookie-frosting"
},
"isAssembledFromMaterialLot": [
{
"id": "butter-67",
"quantity": 1125,
"quantityUnitOfMeasure": {
"id": "g"
},
"materialDefinition": {
"id": "butter"
}
},
{
"id": "confectioner-sugar-yN",
"quantity": 250,
"quantityUnitOfMeasure": {
"id": "g"
},
"materialDefinition": {
"id": "confectioner-sugar"
}
},
{
"id": "peanut-butter-Cq",
"quantity": 2250,
"quantityUnitOfMeasure": {
"id": "g"
},
"materialDefinition": {
"id": "peanut-butter"
}
}
]
},
{
"id": "cookie-dough-Vr",
"quantity": 15000,
"quantityUnitOfMeasure": {
"id": "g"
},
"materialDefinition": {
"id": "cookie-dough"
},
"isAssembledFromMaterialLot": [
{
"id": "egg-gY",
"quantity": 50,
"quantityUnitOfMeasure": {
"id": "large-egg"
},
"materialDefinition": {
"id": "egg"
}
},
{
"id": "flour-kO",
"quantity": 7500,
"quantityUnitOfMeasure": {
"id": "g"
},
"materialDefinition": {
"id": "flour"
}
},
{
"id": "saZ3",
"quantity": 150,
"quantityUnitOfMeasure": {
"id": "g"
},
"materialDefinition": {
"id": "salt"
}
},
{
"id": "sugar-32",
"quantity": 2500,
"quantityUnitOfMeasure": {
"id": "g"
},
"materialDefinition": {
"id": "sugar"
}
},
{
"id": "vanilla-extract-px",
"quantity": 10,
"quantityUnitOfMeasure": {
"id": "g"
},
"materialDefinition": {
"id": "vanilla-extract"
}
}
]
}
]
},
{
"id": "cookie-wrapper-NR",
"quantity": 150,
"quantityUnitOfMeasure": {
"id": "wrapper"
},
"materialDefinition": {
"id": "cookie-wrapper"
},
"isAssembledFromMaterialLot": []
}
]
}
}
}Forward genealogy
A forward genealogy examines the history of how one lot becomes a component of another. For example, if a supplier informs a manufacturer about an issue with a specific raw material, the manufacturer can run a forward genealogy that looks at the downstream material that consumed these bad lots.
In Rhize, you can query the forward genealogy through the isComponentOfMaterialLot property,
using nesting to indicate the number of levels of forward generations.
For example, this query returns the full chain of material that contains (or contains material that contains)
the material sublot peanut-butter-Cq:
query GetMaterialLot($getMaterialLotId: String) {
getMaterialLot(id: "peanut-butter-Cq") {
id
isComponentOfMaterialLot {
id
isComponentOfMaterialLot {
id
isComponentOfMaterialLot {
id
}
}
}
}
}This query returns data in the following structure:
{
"data": {
"getMaterialLot": {
"id": "peanut-butter-Cq",
"isComponentOfMaterialLot": {
"id": "cookie-frosting-9Q",
"isComponentOfMaterialLot": {
"id": "cookie-unit-dh",
"isComponentOfMaterialLot": {
"id": "cookie-box-2f"
}
}
}
}
}
}Next steps: display and analyze
The preceding steps are all you need to create a data foundation to use Rhize for genealogy. After you’ve started collecting data, you can use the genealogy queries to build frontends and isolate entities for more detailed tracing and performance analysis.
Build frontends
All data that you store in the Rhize DB is exposed through the GraphQL API. This provides a flexible way to create custom frontends to organize your genealogical analysis in the presentation that makes sense for your use case. For example, you might represent the genealogy in any of the following ways:
- In a summary report, providing a brief list of the material and all impacted upstream or downstream lots
- As an interactive list, which you can expand to view a lot’s associated quantities, job order, personnel and so on
- As the input for a secondary query
- In a display using some data visualization library
For a visual example, the interactive chart in the introduction takes the data from the preceding reverse-genealogy query, transforms it with a JSONata expression, and visualizes the relationship using Apache echarts.
The JSONata expression accepts an array of material lots,
then recursively renames all IDs and isAssembledFrom properties to name and children, the data structure expected by the visualization.
Additional properties remain to provide context in the chart’s tooltips.
(
$makeParent := function($data){
$data.{
"name": id,
"value": quantity & " " & quantityUnitOfMeasure.id,
"definition": materialDefinition.id,
"children": $makeParent(isAssembledFromMaterialLot)
}
};
$makeParent($.data.getMaterialLot)
)We’ve also embedded Echarts in Grafana workspaces to make interactive dashboards for forward and reverse genealogies:
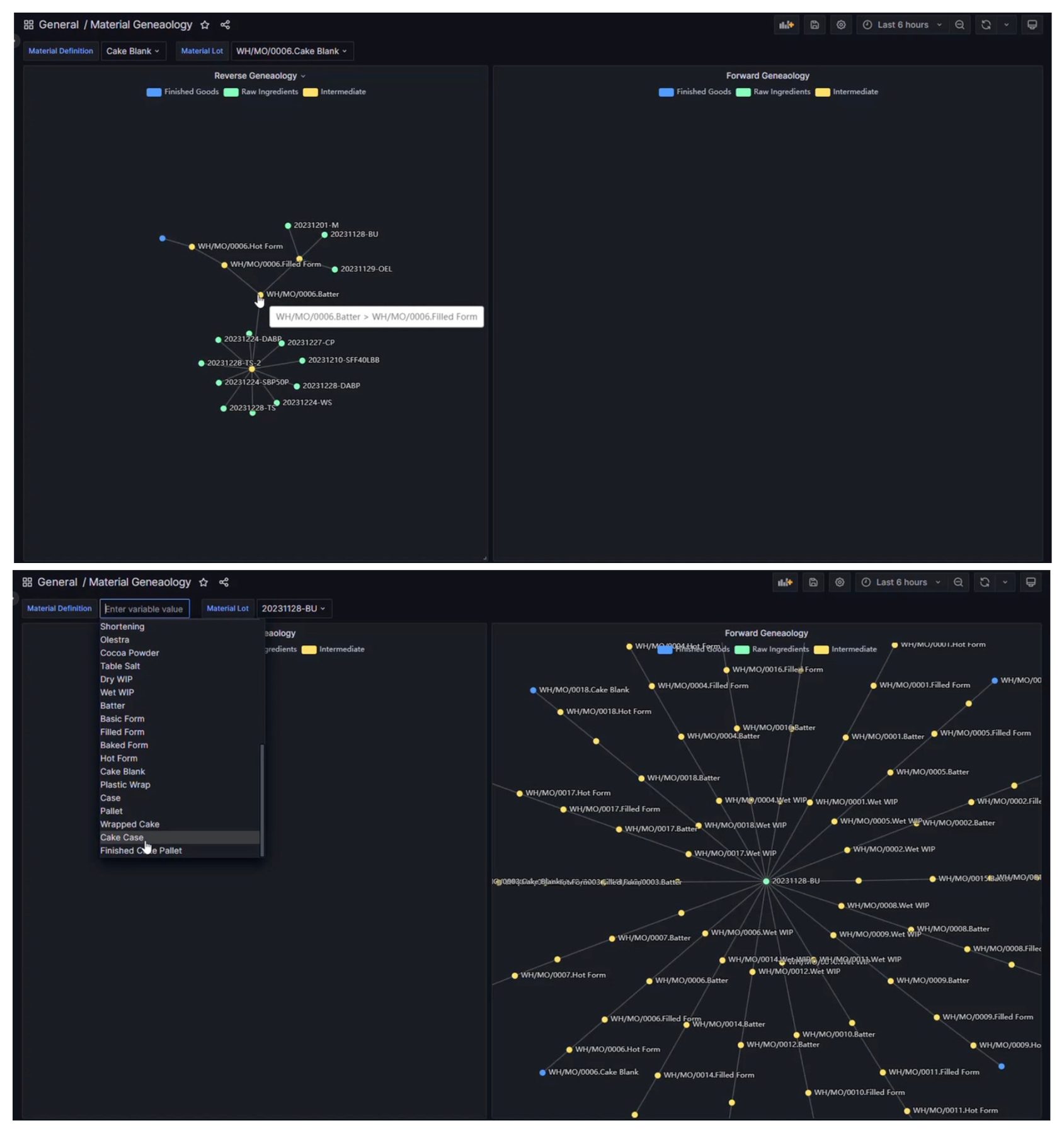
Combine with granular tracing and performance analysis
While a genealogy is an effective tool on its own, the usefulness of the Rhize data hub compounds with each use case. So genealogy implementations are most effective if you can combine them with the other data stored in your manufacturing knowledge graph.
For example, the genealogical record may provide the input for more granular track and trace , in which you use the Lot IDs to determine track material movement across equipment and storage, associated personnel, and so on.
You could also combine genealogy with performance analysis, using the genealogical record as the starting point to analyze and predict failures and deviations.